
获取图像质量和文件大小最优平衡核心产品.目标高品质图像与小带宽并存图像质量和文件大小之间的良好平衡对用户体验至关重要贝斯特2200娱乐电子商务平台依赖高质量产品图像驱动销售,但也快速加载页数避免用户厌倦等待
以人对图像质量感知为基础 开发全新AI优化解决方案
人工智能只像训练数据一样好, 第一部分,我们将深入下潜 深入到我们如何收集数据 训练新图像优化AI引擎
将图像压缩成小文件大小同时保留原创高质量如今很容易使用,多亏WEBP、AVIF和高老JPEG等现代图像压缩编解码器
搭建图像优化引擎 正确使用现代压缩算法 难点部分有效图像优化质量和带宽基本意指了解可应用到图像以最小化文件大小而不减质量的确切压缩量为了实现这一点,人们需要某种规则或启发性来评估图像质量需要量度,具体指IQA(图像质量评估)度量强效IQA可驱动图像优化引擎,选择格式、设置、压缩级等
人以前研究IQA度量,何不使用呢?
确实有多种现代和经典IQA度量数,但这些度量均不适应我们的场景这些指标的构建和开发考虑到各种不同的曲解和人工制品,但几乎完全不对应图像压缩唯一选择就是创建我们自己新的IQA度量了解压缩相关问题、细微差别,并理解它们如何转化成人对图像质量感知
开发AI基础IQA度量要求适当的数据集用于培训和评价可我们认为相对直截了当的一步, 证明是一个重要里程碑 需要大量思考和研究
象任何其他计算机视觉数据集一样,第一步是收集一组有代表性的图像。贝斯特2200娱乐并用Getty或Pexels等广受欢迎的股票图像平台查找不难

下一步我们用各种图像编码器编码/压缩这些图像为了遍历质量频谱,我们使用了许多不同编码器,并有各种设置,包括老式和现代式、广受欢迎和位置式图集原创图像集
贝斯特登录入口官网下载Cloudinary分享相当多资源, 你可以透过博客文章、出版物和文档深入探索。
但这些图片和多相匹配压缩变异,我们如何分配质量分数?我们需要实数质量值与人感知相匹配
众多IQA论文都使用描述图像质量范式
PieApp并PIPAL后台CVRNTIRE讲习相对比较注释方法使用人工注解器对多对图像进行比较之后,所有这些比较都归并成单头板 每一图象都分分数取胜数
这种方法拥有简单性的好处,用户只需从给定配中选择更美图像。其主要劣势不是严格映射定值范围考虑一对比较, 即使是图像分数最低 可能仍然高品质碰巧比所有图片都差一点

另一些方法使用主观注解,又称平均值评分(MOS)注释使用多数据集常用法卡迪德10k,NIMA系统等)简单概念难执行造纸.长话短说MOS注解既贵又吵尽管如此,这种方法的好处是完全基于人对质量的认识

我们决定合并这些范式 构建IQA文库MOS部分会帮助我们锚定数据集对人感知吸引力 相对比较部分则用于 真正捕捉所有细微差别
贝斯特2200娱乐此时点,剩下的就是向众包平台提交注解过程
为了执行高效AI培训,你希望数据尽可能准确性贝斯特2200娱乐正因如此,我们从平台获取注解时首先做的就是探索新数据集我们搭建UI工具分析不同统计,验证前置假设,并学习新事物 关于人感知和它受不同压缩设置影响
并发现少数问题/问题 与注解精度相关
任何AI从业者都知道一切取决于数据质量,即使是最强架构,如果训练不良地面实情则会大失所望
贝斯特2200娱乐不幸地,众包平台 总是有漏洞参赛者 加入你的任务用户向地面事实注解注入大量噪声,可能妨碍对模型进行精确培训
正像所说,我们的目标是探索图像质量的整个范围,并使用不同的压缩设置如何影响图像质量。任务处理明显良好或明显劣质时很容易实现。自大用户做正经工作以来 流氓用户的存在 并不会极大影响图象评分处理中质量图像时并非如此中质量,对这些图像质量没有明确的共识, 拥有足够大无赖用户注解, 无法获取准确质量评分。
参考下例 第一和第二图像MOS似乎合理 考虑分数直方图mos分配到中质量的最后图像似乎不正确,因为对图像质量显然有两种不同观点,而没有一个为5.5。
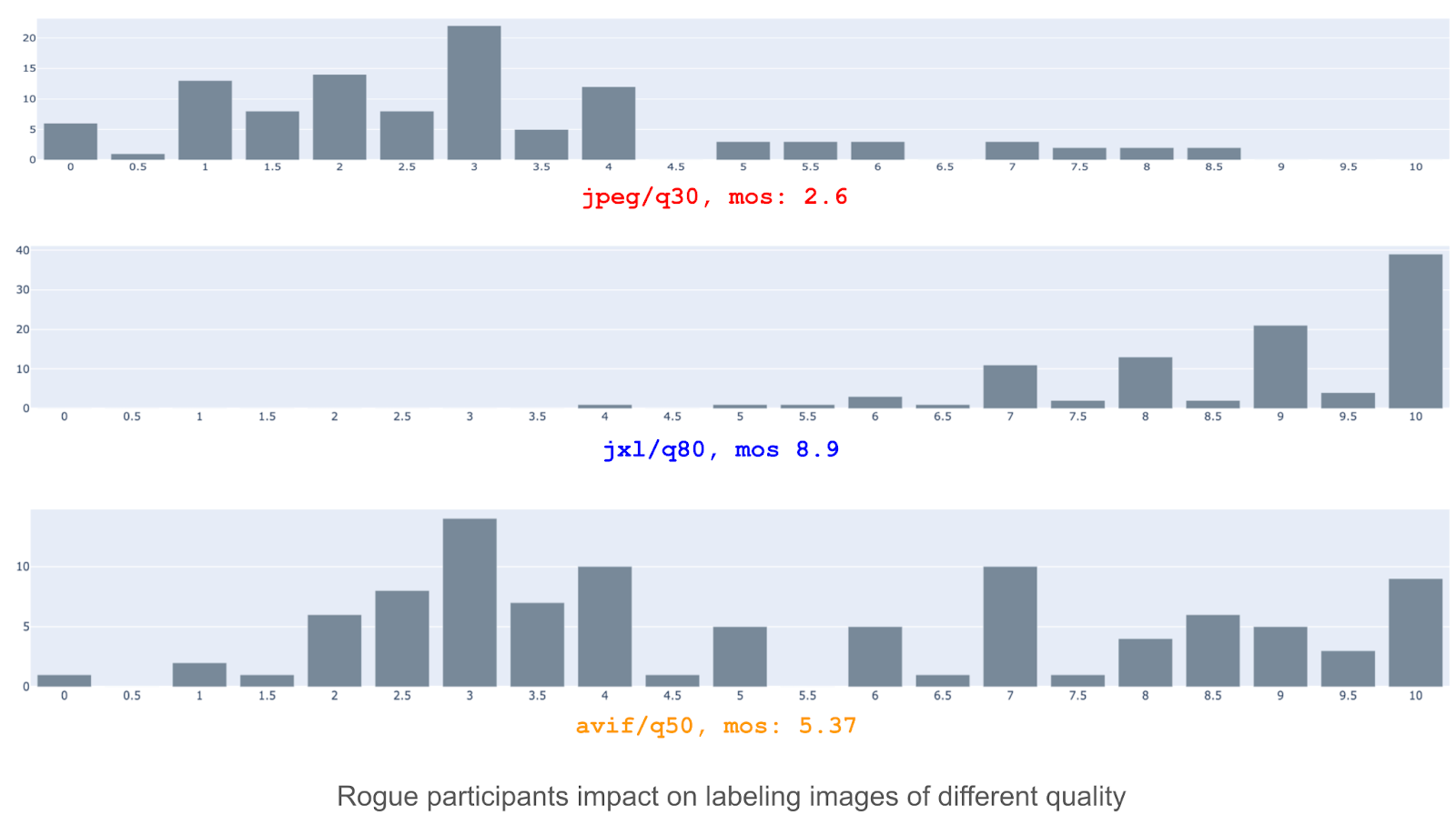
我们理解,我们必须清除注解中的流氓用户,但是我们如何检测到这些用户?
其中一些很容易检测使用预定义测试隐藏注解任务中,例如分级原创图像或分级同映两次简单实践指向参与者,从文体中清除
除隐藏测试外,我们还根据单个参与者简介注解分析,并分析它们与其他参与者的对比方式泛型概念是流氓用户随机注解 总是与所有其他参赛者 严重冲突
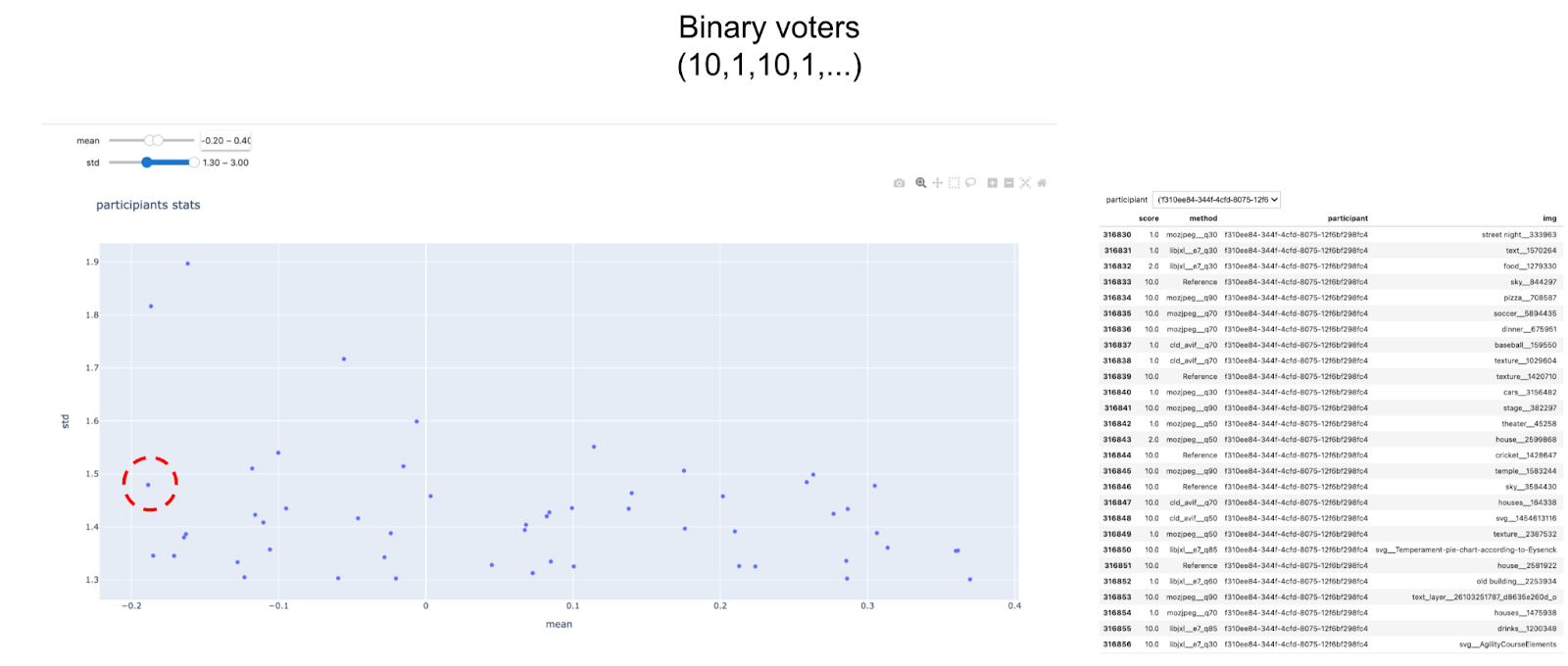
为了澄清,对每位参赛者而言,我们计算MOS单元中分配给图像分数与所有其他参赛者为同类图像平均分数之差。之后,我们用这些差差平均和标准偏差代表每位参赛者并绘制成二维网格

这一数字启发人并显示不同类型的参与者我们用黑破折线标记每个分组阈值
- 随机投票.参与者简介显示,这些简介与所有其他用户经常大相径庭。随机点击方式 遍历注解任务
- 二分投票.总的来说,这些参赛者与所有其他参赛者持平,但根据他们的 std,他们只分极低或高分明显不努力真正分配图片精确分数
- 双用户.与一般观点一致,但按平均距离计算,这些用户与其他用户相比,往往过分原谅或判断力过强。
- 质量用户.用户认真对待工作并始终与大意一致
基于对不同参与者简介的这些洞察力并发数据集,我们做了以下工作:
- 随机二进制投票人 微信微信从参赛者注解中学习
- 微偏差用户,小标定大有助于减少注解中的偏差
观察有争议测试箱时清晰可见这些步骤的影响,例如此示例中

显示真噪声消除

下一篇文章中,我们将更多地分享我们如何训练IQA模型使用两种注解、主观度量和相对值,并分享我们用所学IQA度量能实现什么
